


After the open source launch of the DeepSeek V4 preview version, the AI circle ushered in the "China moment".
DeepSeek V4 has released two versions simultaneously - V4-Pro (1.6 trillion parameters) and V4-Flash (284 billion parameters), both of which support 1 million tokens of ultra-long context.
What's even more shocking is that it does 90% of the performance without using 1% of the price of the top closed-source model - especially in the field of code, directly rushing into the world's first echelon.
|DeepSeek V4 performs well, and its cost performance has sparked heated discussions
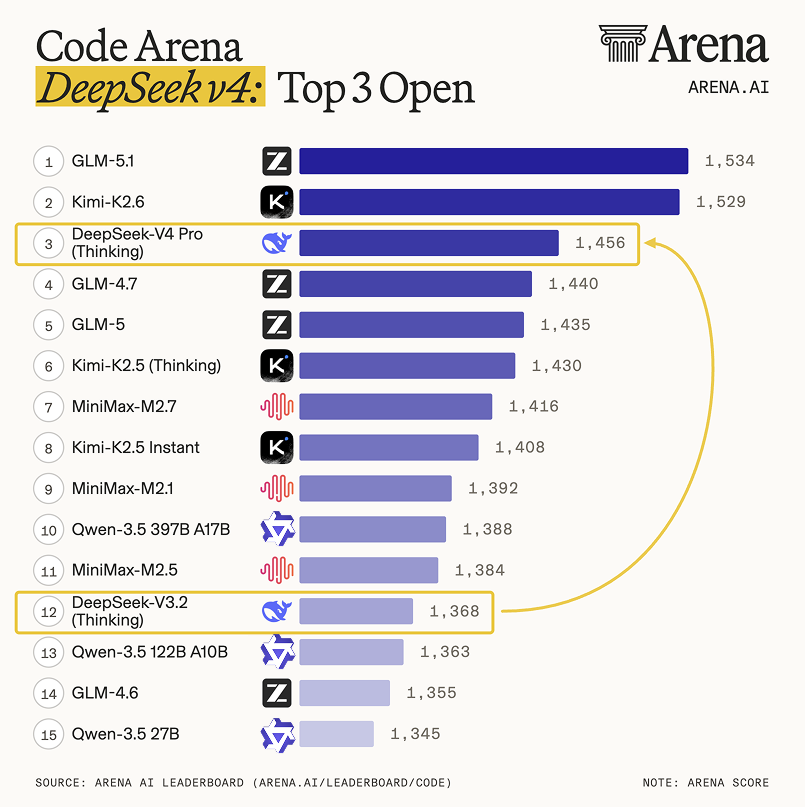
According to third-party reviews: Arena.ai commented on X (formerly Twitter) that V4 Pro (Thinking Mode) is "a huge leap compared to V3.2", ranking 3rd in the open source model and 14th overall in the code capability rankings.
Vals AI said that V4 overwhelmingly won the first place in its open source model in its code test list (Vibe Code Benchmark), even surpassing large closed-source models such as Gemini 3.1 Pro, and its performance was improved by about 10 times compared to the previous generation V3.2.
User feedback began to diverge:
Many netizens called it "cost-effective through the floor" on X, thinking it was too worthwhile.
However, DeepSeek officials are very cautious, stating in the introduction material that the current model is close to the top closed-source system in terms of knowledge and reasoning capabilities, but it is still about 3–6 months behind; Limited by high-end computing power, V4-Pro has limited service capacity.
In short: strong performance and low price, but the official reminder - don't expect it to be completely benchmarked against the strongest closed-source model, and it is still catching up.
The price is super low, and it may be cheaper in the future
The most attractive thing about DeepSeek this time is not only the performance, but also the surprisingly low price.
V4-Flash (Small Model):
Input: $0.14 per million tokens Output: $0.28 per million tokens
It is cheaper than OpenAI's GPT-5.4 Nano and Gemini 3.1 Flash-Lite, making it the cheapest among current small models.
V4-Pro (large model):
Input: $1.74 / Output: $3.48 (per million tokens)
It's much lower than Gemini 3.1 Pro ($12 output), GPT-5.4 ($15), Claude Sonnet 4.6 ($15), and Claude Opus 4.7 ($25).
Technology blogger Simon Willison summed it up: V4-Pro is the most cost-effective choice among all the current top large models.
Why is it so cheap?
DeepSeek says this is due to their extreme optimization in handling ultra-long text (1 million tokens):
The computational volume of V4-Pro is only 27% of that of the previous generation V3.2, and the memory usage (KV cache) is reduced to 10%; V4-Flash is more exaggerated, with only 10% and 7%, respectively.
Moreover, the price may drop!
The official specifically mentioned in the description: "The current service capacity of V4-Pro is limited, mainly due to the lack of high-end computing power. It is expected that in the second half of this year, with the large-scale launch of the domestic Ascend 950 super node, the price of the Pro version will be significantly reduced. ”
To put it simply: it is already the floor price, but there may be a basement under the floor.
The new architecture breaks through the bottleneck of long texts and is also adapted to domestic chips
The core technological breakthrough of DeepSeek-V4 is its first hybrid attention mechanism, called CSA + HCA. This design specifically solves a long-standing problem: when traditional large models process ultra-long texts (such as 1 million words), the amount of computation and memory consumption will "explode", which is not practical at all.
CSA (Compressed Sparse Attention):
Compressing every 4 words into an "information package" and only picking the most relevant parts to calculate not only retains the intermediate details, but also greatly reduces the amount of calculation.
HCA (Severe Compressed Attention):
The entire ultra-long text is further condensed into several "skeleton-level" key information blocks to grasp the overall logic and is suitable for macroscopic reasoning.
In addition to the attention mechanic, V4 also makes two important upgrades:
Introducing mHC manifold constraint connections: more stable than traditional "residual connections", which can make signals more efficient in the model; Use the Muon optimizer: It replaces the common AdamW, which is more suitable for training large "expert hybrid" (MoE) models like V4, and can also support low-precision training and save resources.
Together, these optimizations can increase inference speed by up to 2 times. More importantly, it runs on domestic chips!
DeepSeek-V4 has been deeply optimized on Huawei's Ascend NPU, which is 1.5 to 1.73 times faster in ordinary inference tasks through "fine-grained expert parallelism" technology.
Officially, this is the world's first trillion-parameter open-source model to complete training and inference on domestic computing power.
However, the optimization code of the Ascend platform is not open source and is a closed-source acceleration solution.
On the other hand, Cambrian has completed support for V4-Flash and V4-Pro through the open-source framework vLLM, and the relevant code is already open source on GitHub, and developers can use it directly.
Jingtai View|Focus on three main lines, one signal
Main line 1: Domestic AI chips and computing power ecology
Huawei's Ascend industry chain: chips, servers, liquid cooling, cluster operation and maintenance; Cambrian, Tianshu Zhixin: benefiting from the wave of model adaptation; Domestic AI cloud service providers: Platforms that provide Ascend computing power leasing will explode.
Main line 2: application layer innovation driven by open source model
AI programming tools, agent development platforms, long text analysis SaaS: V4's low price + high performance will detonate B-end demand; Localized deployment solution: MIT protocol is free for commercial use, and small and medium-sized enterprises can build private models at low cost.
Main line 3: Focus on the reshaping of the "Model as a Service" (MaaS) pattern
DeepSeek challenges OpenAI/Anthropic's pricing power with API+ open source two-wheel drive; Extremely low migration costs for developers (compatible with OpenAI formats), and ecological switching is accelerated.
Risk warning: Multimodal capabilities are temporarily lacking (plain text), and the initial supply of the Pro version is tight.



